什么是伪共享
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解缓存行和对象的内存布局,有关缓存行和对象内存布局可以参考我的另外两篇文章理解CPU Cache和Java对象内存布局。
下面的图说明了伪共享的问题:
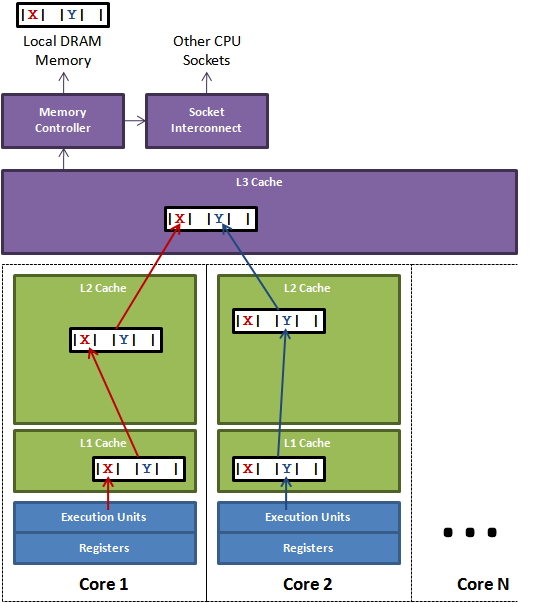
假设在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
避免伪共享
假设有一个类中,只有一个long类型的变量:
|
|
这时定义一个VolatileLong类型的数组,然后让多个线程同时并发访问这个数组,这时可以想到,在多个线程同时处理数据时,数组中的多个VolatileLong对象可能存在同一个缓存行中,通过上文可知,这种情况就是伪共享。
怎么样避免呢?在Java 7之前,可以在属性的前后进行padding,例如:
|
|
通过Java对象内存布局文章中结尾对paddign的分析可知,由于都是long类型的变量,这里就是按照声明的顺序分配内存,那么这可以保证在同一个缓存行中只有一个VolatileLong对象。
这里有一个问题:据说Java7优化了无用字段,会使这种形式的补位无效,但经过测试,无论是在JDK 1.7 还是 JDK 1.8中,这种形式都是有效的。网上有关伪共享的文章基本都是来自Martin的两篇博客,这种优化方式也是在他的博客中提到的。但国内的文章貌似根本就没有验证过而直接引用了此观点,这也确实迷惑了一大批同学!
在Java 8中,提供了@sun.misc.Contended注解来避免伪共享,原理是在使用此注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。具体可以参考http://mail.openjdk.java.net/pipermail/hotspot-dev/2012-November/007309.html。
下面用代码来看一下加padding和不加的效果:
运行环境:JDK 1.8,macOS 10.12.4,2.2 GHz Intel Core i7,四核-八线程
|
|
VolatileLong对象只有一个long类型的字段,VolatileLong2加了padding,下面分别执行看下时间:
|
|
没加padding时用了大概57秒,加padding后用时大概4.6秒,可见加padding后有效果了。
在Java8中提供了@sun.misc.Contended来避免伪共享,例如这里的VolatileLong3,在运行时需要设置JVM启动参数-XX:-RestrictContended,运行一下结果如下:
|
|
结果与加padding的时间差不多。
下面看一下VolatileLong对象在运行时的内存大小(参考Java对象内存布局):

再来看下VolatileLong2对象在运行时的内存大小:

因为多了14个long类型的变量,所以24+8*14=136字节。
下面再来看下使用@sun.misc.Contended注解后的对象内存大小:

在堆内存中并没有看到对变量进行padding,大小与VolatileLong对象是一样的。
这就奇怪了,看起来与VolatileLong没什么不一样,但看一下内存的地址,用十六进制算一下,两个VolatileLong对象地址相差24字节,而两个VolatileLong3对象地址相差280字节。这就是前面提到的@sun.misc.Contended注解会在对象或字段的前后各增加128字节大小的padding,那么padding的大小就是256字节,再加上对象的大小24字节,结果就是280字节,所以确实是增加padding了。
八线程运行比四线程运行还快?
根据上面的代码,把NUM_THREADS改为8,测试看下结果:
|
|
可以看到,加了padding和@sun.misc.Contended注解的运行时间多了不到1倍,而VolatileLong运行的时间比线程数是4的时候还要短,这是为什么呢?
再说一下,我的CPU是四核八线程,每个核有一个L1 Cache,那么我的环境一共有4个L1 Cache,所以,2个CPU线程会共享同一个L1 Cache;由于VolatileLong对象占用24字节内存,而代码中VolatileLong对象是保存在数组中的,所以内存是连续的,2个VolatileLong对象的大小是48字节,这样一来,对于缓存行大小是64字节来说,每个缓存行只能存放2个VolatileLong对象。
通过上面的分析可知,伪共享发生在L3 Cache,如果每个核操作的数据不在同一个缓存行中,那么就会避免伪共享的发生,所以,8个线程的情况下其实是CPU线程共享了L1 Cache,所以执行的时间可能比4线程的情况还要短。下面看下执行时4线程和8线程的CPU使用情况:
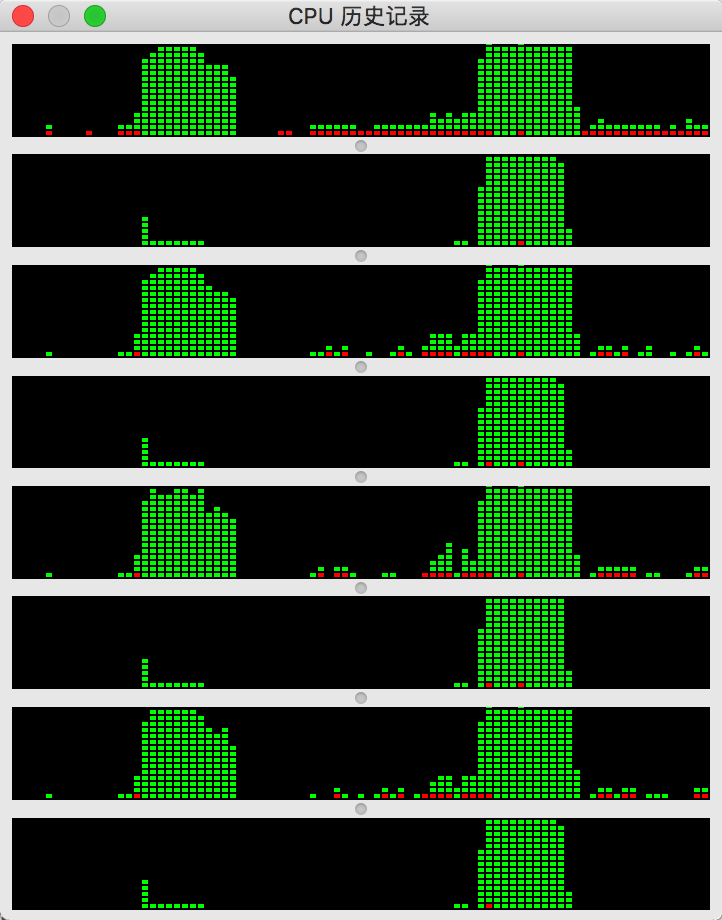
可以看到,在4线程时,线程被平均分配到了4个核中,这样一来,L1 Cache肯定是不能共享的,这时会发生伪共享;而8线程时,每个核都使用了2个线程,这时L1 Cache是可以共享的,这在一定程度上能减少伪共享的发生,从而时间会变短(也不一定,但总体来说8线程的情况与4线程的运行时间几乎不会向加padding和注解的方式差那么多)。
在Windows上情况就不太一样了,在双核四线程的CPU上,测试结果并不和mac中一样,在不加padding和注解时,2线程和4线程执行的时间都是将近差了1倍,看下使用2个线程在Windows中执行的时候CPU的使用情况:
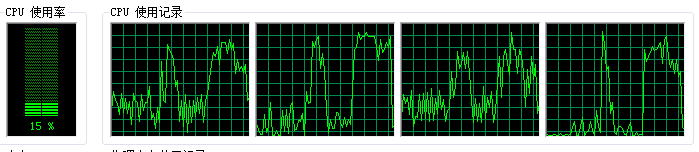
虽然只使用了2个线程,但从图像上来看,似乎都在工作,即使把线程数量设置为1也是这种情况。这应该是Windows和UNIX对CPU线程调度的方式不一样,具体我现在也不太清楚他们之间的差别,希望有知道的同学告知,感谢。
@sun.misc.Contended注解
上文中将@sun.misc.Contended注解用在了对象上,@sun.misc.Contended注解还可以指定某个字段,并且可以为字段进行分组,下面通过代码来看下:
|
|
这里还是使用到了classmexer.jar,可以参考Java对象内存布局中的说明。
这里在变量b和c中使用了@sun.misc.Contended注解,并将这两个变量分为1组,执行结果如下:
|
|
可见int类型的变量的偏移地址是12,也就是在对象头后面,因为它正好是4个字节,然后是变量a。@sun.misc.Contended注解的变量会加到对象的最后面,这里就是b和c了,那么b的偏移地址是152,之前说过@sun.misc.Contended注解会在变量前后各加128字节,而byte类型的变量a分配完内存后这时起始地址应该是从17开始,因为byte类型占1字节,那么应该补齐到24,所以b的起始地址是24+128=152,而c的前面并不用加128字节,因为b和c被分为了同一组。
我们算一下c分配完内存后,这时的地址应该到了168,然后再加128字节,最后大小就是296。内存结构如下:
| d:12~16 | — | a:16~17 | — | 17~24 | — | 24~152 | — | b:152~160 | — | c:160~168 | — | 168~296 |
现在把b和c分配到不同的组中,代码做如下修改:
|
|
运行结果如下:
|
|
可以看到,这时b和c中增加了128字节的padding,结构也就变成了:
| d:12~16 | — | a:16~17 | — | 17~24 | — | 24~152 | — | b:152~160 | — | 160~288 | — | c:288~296 | — | 296~424 |